

監視資本主義 Surveillance Capitalism とデジタルレーニン主義 Digital Leninism
監視資本主義とは、個人が意図せずに提供したパーソナルデータの集中管理に基づいて、AIが個人に介入することを指す。2016年のイギリスのBrexitの国民投票、あるいはアメリカの大統領選挙などがこれに該当する。これらの投票の勝った方の裏側では、Cambridge Analyticaというイギリスの選挙コンサルティング会社が暗躍していた。Facebookの友達APIを使って、利用者の友達の情報を不正に収集し、マイクロターゲティングをかけていたのだ。この手法がさらに洗練されてくると、最終的に個人の投票をかなり左右してしまう、という懸念がある。
一方、デジタルレーニン主義はCentralized AIを使った権威主義的な統治のことを指す。典型的なのが中国で、中国の芝麻信用あるいは民間の信用サービスであれば個人は使わないという判断も可能だが、これらは政府が運用する社会信用システムなので、中国人はここから逃れられない。街中の監視システムも高度に発達している。
しかしこれらを国際協調で抑制するのは無理だろう。勝者を産むからだ。つまり特定の企業や国家に巨大な利益や覇権をもたらし得るので、核戦争や地球温暖化のように「勝者を産まない」ものとは決定的に異なる。従って話し合いが成立しない。
Personal AI(PAI)とは何か
私が考えたPersonal AIは、各個人に帰属し、生まれる前から死んだあとまで本人の面倒を見てくれるアシスタントだ。個人のパーソナルデータ管理を全てPersonal AIを任せることになる。Personal AIは、そのパーソナルデータをフル活用して、本人だけに深く、きめ細かく介入し、意思決定と行動ないしは行動変容を支援する。商品・サービス・職業等の選択、あるいは生活習慣の改善やヘルスリテラシーの向上等々、いろいろなことを支援してくれるだろう。Centralized AIよりも詳しく、かつセンシティブなデータを使うことになるので、サービスレベルが極めて高くなる。ただし厳格なガバナンスとセットで導入しないと大きな損害を与える可能性もあるので、使い方や運用には注意が必要だ。
付加価値:PAI>>CAI
今まで、サービス提供者はP1からPnまでがCentralized AI、K1(knowledge)からKnを使って、かつパーソナルデータの種類D1からDnを組み合わせてサービスを提供してきた。例えば、P1はK1とD1の組み合わせによってサービスを提供し、PnはKnとDnを組み合わせてサービスを提供してきた。それによってn種類のサービスが提供されていたが、このK1からKn、それからD1からDnをすべて個人のこのPersonal AI に集約すると、Personal AIはK1からプラスαの知識を使ってD1からDnプラスαのパーソナルデータに照らしてサービスを提供できるので、最大(n+1)2種類のサービスが提供できる。もちろん無意味な組み合わせもあるので、(n+1)2にはならないがnよりははるかに多い種類のサービスを提供することができる。例えば、採寸データを使って健康管理するというようなことが可能だ。
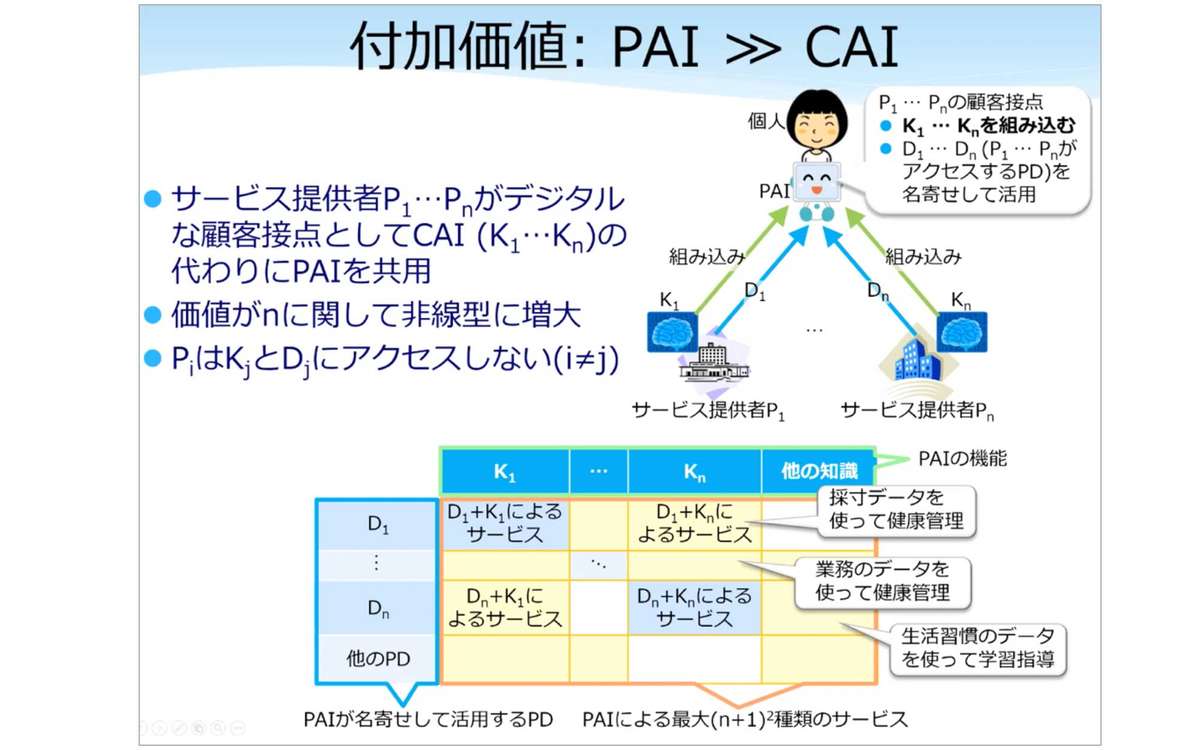
例えばDnとK1の組み合わせによって提供されるサービスからあがった儲けは、P1とPnが山分けすればいいので、サービス提供者もよりたくさん儲かるようになるはずだ。ここで、この知識を各個人のPAIが個別に集約するのは効率が悪いので、知識の集約は知識メディエータという別の事業者がやるほうがいいだろう。
Amazonあんしんメールというサービスがある。これは、Amazonでオムツとハチミツを買うと、あとでAmazonからメールが来て「赤ちゃんにハチミツをあげてはだめですよ」と教えてくれる。ハチミツにはボツリヌス菌がいるので、1歳未満の乳児に与えると、乳児ボツリヌス症という病気になって死ぬリスクがあるのだ。問題はそのメールを受け取れるためにはオムツとハチミツ両方をAmazonで買う必要がある、ということだ。私たちは特定のECサイトにロック��インされたいと思っている訳ではない。オムツもハチミツもそれぞれ別のところで購入したいと考えるほうがむしろ自然だ。こういうシーンでPersonal AIはその威力を発揮する。購買記録を全部知っていれば、Amazonと同じようなあるいはそれを上回るサービスが提供できるだろう。無論そのための知識、つまり乳児ボツリヌス症に関する「家庭の医学」のような知識をも集約する必要があるが、この点だけはChatGPTを使えばいい、ということになる(現時点での性能では若干問題があると思われるが)。
この知識メディエータがアパレルメーカーから、既製服の情報、例えば採寸データとか色とか生地、デザインなどの情報を集める。それで、この人が仕立屋さんで採寸してもらって、そのデータを手元のPAIで管理しているとする。そして知識メディエータがこの情報を集めてつくった既製服のカタログ、知識の集約をこのPersonal AIがダウンロードして、手元でマッチングし、本人に合う既製服を推薦する。本人がその服を気に入ったらば、アパレルメーカーから買って、代金をメディエータ経由で支払う。メディエータは手数料を抜いて代金をアパレルメーカーに送金する。このメディエータは手数料分、儲かるわけだが、その儲けには仕立屋さんも貢献している。そこで仕立屋さんにも手数料を分配すれば、仕立屋さんはお客さんのパーソナルデータ(採寸データ)を本人に提供することによって儲かるということになる。そうすればパーソナルデータが本人に集約されるというエコシステムが回り始めるだろう。分散型のAmazonだと考えて貰えば良い。
ただし、障害になりそうなのは「企業は一人勝ち��を指向しがちだ」という点にある。データと顧客を囲い込むビジネスに慣れているからだろう。しかし先に述べたエコシステムが回り始めると実はそっちの方が儲かる、ということがわかるはずだ。しかもこれはPersonal AIを経由しているので、カルテルでもトラストでもなく、あくまで合法的な手段である。
オープン市民科学の社会実装を目指す
いろいろなサービス提供者から本人のデータが各個人のところに集約され、本人に集約されたデータを各個人の意思でサービスを設計したり、あるいは監査する人たちに開示することができるようになる。このとき重要なのは、AIの出力やサービスから各個人に対する介入に関するデータも含むパーソナルデータをデータポータビリティの対象にする、ということだろう。例えばChatGPTと会話するときに、ChatGPTの答えも含むパーソナルデータを本人の意思でいろいろな人に開示することができるようにすることだ。特に、サービスの設計者や監査者に開示することができる、という機能が重要になる。 それによって、このサービスを監査する人たち、例えばPersonal AIがいろいろな個人に対してどのように介入して、その結果、個人にとってメリットがもたらされているのか、あるいはデメリットが生じているのかということを分析し、その分析の結果、このPersonal AIあるいはサービスが本人の役に立っていないじゃないかという場合には改善させる、ということが可能になる。これは同時に商品やサービスの開発、人間や社会に関する研究、あるいは政策の立案と検証などに使うことができる。つま��り世の中の基盤になるということを意味する。
ここで重要なのは、サービスの設計者、監査者に対しては天下りに権威が与えられているわけではなく、この人たちはお互いの分析結果のチェック&バランスを施すことで相互の社会的な信用を分権的に築いていくことになるということだ。これこそが民主的なデータの使い方ではないだろうか。
データの中立性は、個人がデータを持っていて、それをいろいろな事業者から中立な立場、つまり本人の立場でデータを管理している状態だ。それを自由に使える、中立であるからこそ自由に使える、本人のために使えて、かつサービスの監査にも使える、ガバナンスにも使えるということだ。
※この記事は、2023年5月31日に実施したオンラインイベント「データ民主化の方法論(Democratic Data Day Spring2023)」 における橋田氏の講演の一部を記事としてまとめたものです。映像は現在見逃し配信を実施しています。ご興味のある方はこちらのフォームから登録いただけると無料でご覧いただけます。
(Modern Times編集部)
参照リンク
世界最大級のプライバシー事件「ケンブリッジ・アナリティカ問題」とは何だったのか(プライバシーテック研究所)









